
Understanding the Privacy Risks of Popular Search Engine Advertising Systems:Measurement Methodology
:::info
This paper is available on arxiv under CC0 1.0 DEED license.
Authors:
(1) Salim Chouaki, LIX, CNRS, Inria, Ecole Polytechnique, Institut Polytechnique de Paris;
(2) Oana Goga, LIX, CNRS, Inria, Ecole Polytechnique, Institut Polytechnique de Paris;
(3) Hamed Haddadi, Imperial College London, Brave Software;
(4) Peter Snyder, Brave Software.
:::
Table of Links
Abstract and Introduction
Background
Measurement Methodology
Results
Limitations
Related Work
Conclusion, Acknowledgments, and References
Appendix
3 MEASUREMENT METHODOLOGY
We develop a measurement methodology to capture network flows when clicking on an ad from a search engine results page. Using multiple crawlers, we simulate a large number of search engine queries in order to collect a sample of information flows per search engine. For each request, we collect the cookies created, the locally stored values, and the web request sent by the browser. In addition, we rely on several open-source datasets to detect web requests to online trackers. We consider five main search engines: Google[1], Bing[2], DuckDuckGo[3], StartPage[4], and Qwant[5]. We use Google and Bing as baselines to compare with the other three, which claim to have higher privacy standards and protective measures in place.
\
\
3.1 Crawling system
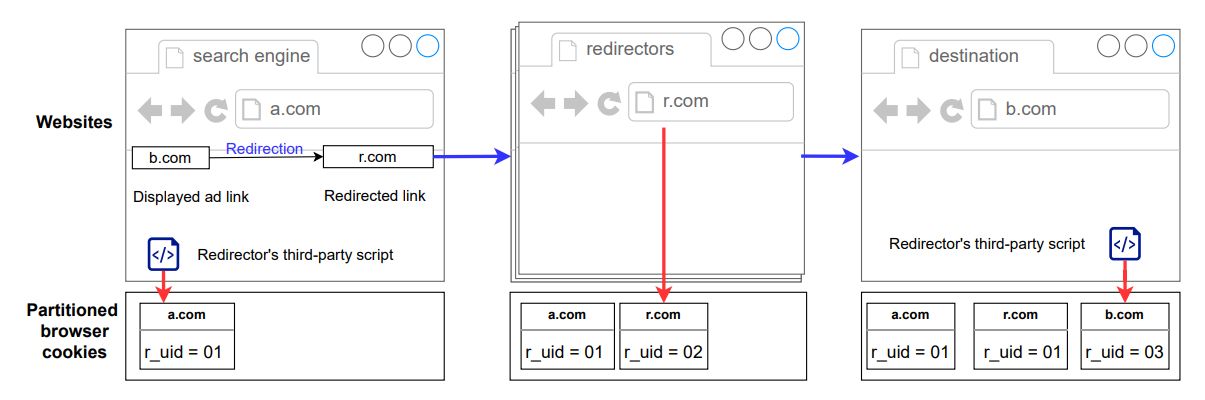
Each crawling iteration begins at a search engine’s main page, where our system will type a query and access the search engine results page. Next, it chooses one of the displayed ads to click on to access its destination website. Then, the navigation path passes through zero or more redirectors before landing on the ad’s destination website. The redirectors are invisible to the user but can be identified through an analysis of network requests initiated by the browser. Each of these redirectors can read the query parameters added by the search engine or other intermediaries and store them locally or send them to other third parties. The system records all first-party and third-party cookies, local storage values, and web requests at each step. We run each iteration in a
new browser instance to ensure no stale data is cached from previous iterations.
\
Depending on the search engine, ads are either part of the main page or are loaded through an iframe. We use scrapping techniques to detect them and rely on several HTML elements’ attributes. For instance, all ads on StartPage are inside an HTML element titled "Sponsored Links". Moreover, we use hyperlink values to detect Google ads since they all link to "www.googleadservices.com/*".
\
Our system prioritizes ads with landing domains it has not visited yet, aiming to maximize the number of different destination websites. Each time a crawler clicks on an ad, our system adds the domain of its landing URL to the list of visited websites. In the subsequent iterations, the crawler first extracts the landing domains of all the displayed ads. The landing domains are included within the HTML objects of the advertisements on all search engines. The crawler then gives preference to click on ads leading to domains that have not been encountered in the list of visited websites.
\
\
We reproduced these steps for 500 search queries on the five search engines. We randomly choose them from Google Trends [21] and movie titles from MovieLens [6]. All iterations were performed in "accept" cookies mode. Table 1 represents the number of different search queries we typed, the number of different destination pages we landed on, and the number of different domain paths we collected for each search engine.
\
We implemented our system using Puppeteer [7] to automate visiting search engines’ websites, typing search queries, detecting and clicking on one of the displayed ads, and waiting for 15 seconds on the ad’s destination website. We reproduce these steps multiple times from the same IP address for each search engine. To reduce the chance of being identified as bots, we use puppeteer-extra-plugin-stealth [8]. This plugin applies various techniques to make the detection of headless Puppeteer crawlers by websites harder.
\
Puppeteer allows us to record cookies and local storage for each request. However, it does not guarantee that it can attach request handlers to a web page before it sends any requests [33]. Hence, detecting and collecting web requests only using Puppeteer might cause losing some of them. We use a Chrome extension alongside Puppeteer crawlers to record web requests during all the crawling time. We do not observe a significant difference between web requests recorded by crawlers and web requests recorded by the extension. In median, the crawlers recorded 97% of the requests recorded by the extension. The code of the crawling system and the dataset are available at https://github.com/CHOUAKIsalim/SearchEnginesPrivacy.
3.2 Detection techniques
Detection of trackers: We use URL filtering to detect web requests to online trackers. We use filter rules from two open-source lists: EasyList [4] and EasyPrivacy [5]. EasyList is the most popular list to detect and remove adverts from webpages and forms the basis of many combination and supplementary filter lists [19]. EasyPrivacy is a supplementary filter list that detects and removes all forms of tracking from the internet, including tracking scripts and information collectors [19]. These filter lists are used by extensions that aim to remove unwanted content from the internet, like AdBlock and uBlock. We combined and parsed these lists using adblock-rs [1] and obtained 86 488 filtering rules.
\
In addition, we use the Disconnect Entity List [2] to get the entities of online tracker domains. It is a dictionary where keys represent entities such as Google, Microsoft, and Facebook, and values represent the web domains that belong to each entity. Hence, to get the entity of a tracker, we iterate over all values and search to what entity is the tracker domain associated with. This list contains 1 449 entities and 3 371 related web domains.
\
Detection of bounce tracking: We classify an instance as bounce tracking when an advertisement’s destination link is altered to pass through one or more redirectors. To construct the redirection sequence, we trace the series of URLs the browser navigates through after clicking an ad and prior to reaching the advertisement’s intended landing page. We further validate the redirection sequence by examining the HTTP response headers, precisely the ’Location’ and ’status code’ headers. These headers divulge the redirection process, as the ’Location’ header contains the new redirection URL, and status codes such as ’301 Moved Permanently,’ ’302 Found,’ ’307 Temporary Redirect,’ and ’308 Permanent Redirect’ indicate the occurrence of redirection [17].
\
Detection of UID smuggling and user identifiers: To detect UID smuggling, we need to differentiate between query parameters that represent user identifiers and non-tracking
query parameters such as session identifiers, dates, and timestamps. We consider all query parameters, localStorage, and cookie values. We call them tokens. There are 6 971 unique
tokens in our dataset. We perform the following filtering, which is similar to the one performed by Randall et al. [33]:
\
(i) Each iteration is executed in a new browser instance; hence, user identifiers should not be shared across browser instances. We discard tokens that are the same across all or a subset of browser instances.
\
(ii) For each browser instance and search query, we analyze the tokens resulting from the URLs of all ads that appear on the results page (which are usually in the form of googleadservices.com/…./aclk?..cid=CAESbeD2ZWCwqFv3e2k_….). We discard tokens with different values for the different ad URLs as they likely correspond to ad identifiers.
\
(iii) To detect session identifiers, we store the profile of each iteration in a separate directory and execute an extra iteration per browser instance one day later to see which values of cookies/parameters change. We discard tokens with different values in the two iterations as they are more likely session identifiers.
\
(iv) Similar to [33], we use programmatic heuristics to discard particular values. We discard tokens that appear to be timestamps (values between June and December 2022 in seconds and milliseconds), tokens that appear to be URLs, tokens that constitute one or more English words ([20]), and tokens that are seven characters long or less.
\
After using these filters, we are left with 1 942 tokens. We manually investigated them and observed a non-negligible number of false positives. Hence, we manually filtered the remaining tokens and removed those composed of any combination of natural language words, coordinates, or acronyms. In the end, we are left with 1 258 user-identifying tokens, which we consider to be user identifiers.
\
\
[1] https://www.google.com/
[2] https://www.bing.com/
[3] https://duckduckgo.com/
[4] https://www.startpage.com
[5] https://www.qwant.com/
Welcome to Billionaire Club Co LLC, your gateway to a brand-new social media experience! Sign up today and dive into over 10,000 fresh daily articles and videos curated just for your enjoyment. Enjoy the ad free experience, unlimited content interactions, and get that coveted blue check verification—all for just $1 a month!
Account Frozen
Your account is frozen. You can still view content but cannot interact with it.
Please go to your settings to update your account status.
Open Profile Settings