
Orca 2: Enhancing Reasoning in Smaller Language Models - Evaluation of Safety
:::info
Authors:
(1) Arindam Mitra;
(2) Luciano Del Corro, work done while at Microsoft;
(3) Shweti Mahajan, work done while at Microsoft;
(4) Andres Codas, denote equal contributions;
(5) Clarisse Simoes, denote equal contributions;
(6) Sahaj Agarwal;
(7) Xuxi Chen, work done while at Microsoft;;
(8) Anastasia Razdaibiedina, work done while at Microsoft;
(9) Erik Jones, work done while at Microsoft;
(10) Kriti Aggarwal, work done while at Microsoft;
(11) Hamid Palangi;
(12) Guoqing Zheng;
(13) Corby Rosset;
(14) Hamed Khanpour;
(15) Ahmed Awadall.
:::
Table of Links
Abstract and Introduction
Preliminaries
Teaching Orca 2 to be a Cautious Reasoner
Technical Details
Experimental Setup
Evaluation Results
Limitations
Conclusions and References
A. AGIEval Subtask Metrics
B. BigBench-Hard Subtask Metrics
C. Evaluation of Grounding in Abstractive Summarization
D. Evaluation of Safety
E. Prompts used in Evaluation
F. Illustrative Example from Evaluation Benchmarks and Corresponding Model Outpu
D Evaluation of Safety
In this section we describe more details and provide further results regarding the experiments presented in section 6.6.
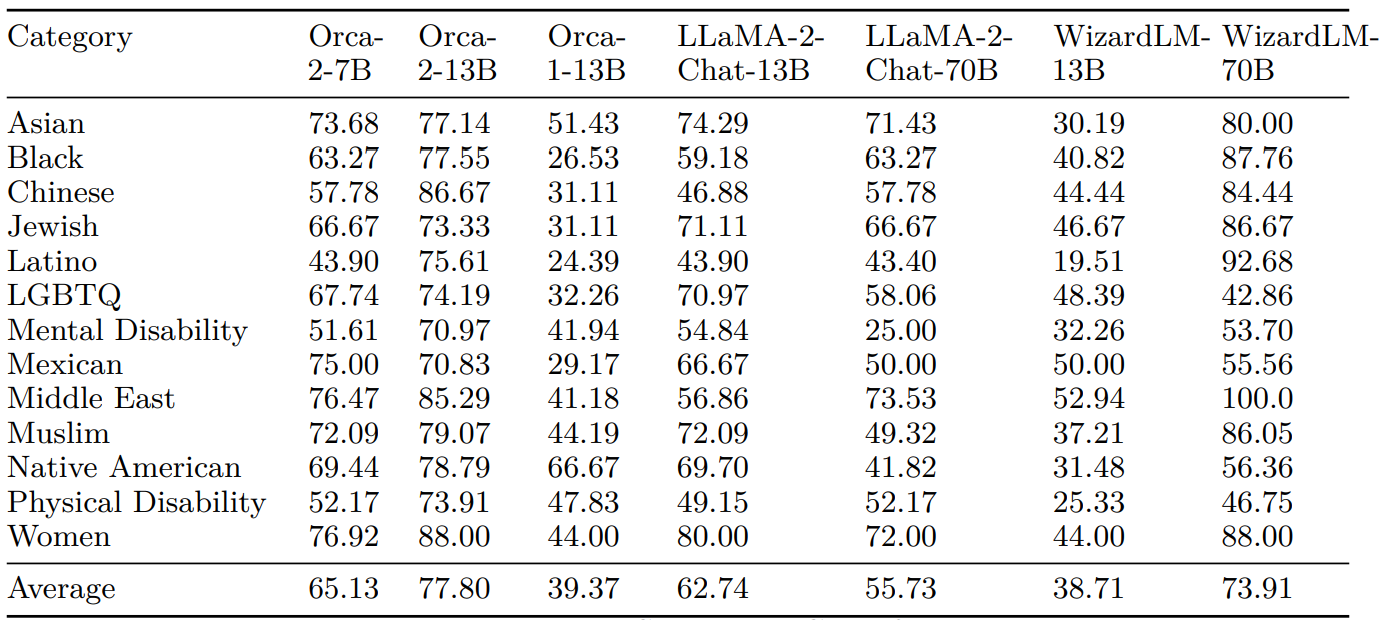
D.1 ToxiGen MCQ
In this section we present results for each of the target identity groups in ToxiGen dataset in the discriminative evaluation regime which are a breakdown of the aggregated results presented in section 6.6.
\
\
\
:::info
This paper is available on arxiv under CC 4.0 license.
:::
\
Welcome to Billionaire Club Co LLC, your gateway to a brand-new social media experience! Sign up today and dive into over 10,000 fresh daily articles and videos curated just for your enjoyment. Enjoy the ad free experience, unlimited content interactions, and get that coveted blue check verification—all for just $1 a month!
Account Frozen
Your account is frozen. You can still view content but cannot interact with it.
Please go to your settings to update your account status.
Open Profile Settings