
Understanding the Privacy Risks of Popular Search Engine Advertising Systems: Results
:::info
This paper is available on arxiv under CC0 1.0 DEED license.
Authors:
(1) Salim Chouaki, LIX, CNRS, Inria, Ecole Polytechnique, Institut Polytechnique de Paris;
(2) Oana Goga, LIX, CNRS, Inria, Ecole Polytechnique, Institut Polytechnique de Paris;
(3) Hamed Haddadi, Imperial College London, Brave Software;
(4) Peter Snyder, Brave Software.
:::
Table of Links
Abstract and Introduction
Background
Measurement Methodology
Results
Limitations
Related Work
Conclusion, Acknowledgments, and References
Appendix
4 RESULTS
This section presents the results of applying the presented methodology to the five selected search engines. We measure how users’ privacy is affected before, during, and after clicking on a search ad. We find that the advertising systems on all evaluated search engines result in privacy harm, even for search engines that market themselves as privacy-respecting. We find that how, and to what degree, user privacy is harmed varies across each evaluated system.
\
The rest of this section proceeds as follows. Section 4.1 begins by presenting measurements of how user privacy is impacted before users click on an ad (i.e., after the user has received answers to their search query, but before the user clicks on an advertisement contained among or alongside the search results). Section 4.2 presents measurements of how user privacy is effected during clicking on an advertisement (i.e., after the user has clicked on an advertisement, but before the user arrives at the advertisement’s destination). Finally, Section 4.3 gives measurements of how user privacy is affected after clicking on an advertisement (i.e., after the user has arrived at the final destination of the advertisement link, and scripts are executed on the advertiser’s website).
4.1 Before clicking on an ad
We first present measurements of how the advertising systems used by popular search engines affect user privacy before a person has clicked on any advertisement. At this point in the process, the user has submitted a query to the search engine and received a results page. The returned results include at least two types of links: “organic results” (i.e., websites that contain content the search engine thinks relates to the query) and “paid results” (i.e., advertisements that the search engine has been paid to show to users).
\
This subsection presents measurements of how user privacy is impacted before the user has clicked on a search advertisement. Since a user will only click on a fraction of the advertisements they are presented with, users will be effected by these “before” privacy harms more frequently than the privacy harms presented in later subsections.
\
4.1.1 First-party reidentification. We first measure whether search engines track or reidentify users across queries and visits. We find that the non-privacy-focused search engines (i.e., Bing and Google) track users across visits and are able to link different search queries to the same user who made those queries. The privacy-focused search engines, on the other hand, do not appear to attempt to reidentify users across visits or queries, aligning with the claims made in their privacy policies (see Section 2.1). We measured whether search engines are able to reidentify users across queries and visits by looking for whether search engines stored unique user identifiers in the browser’s first-party storage (e.g., cookies, localStorage). Specifically, we inspected the DOM storage area for each site and looked for stored values that appeared to be unique identifiers, using the heuristics described in Section 3.2. We observed that Google and Bing did store such user identifiers; the other search engines did not.
\
We note that some privacy-focused search engines did store other values in first-party storage, but that they were used for purposes other than user identification (e.g., clientside storage of user preferences).
\
4.1.2 Requests to trackers. We also measured whether search engines harmed user privacy by communicating with trackers when presenting advertisements. We did not observe any
search engine including resources from, or making network requests to, known trackers.
\
We checked for communication with known trackers by i. recording the URLs of all the network requests made by the browser when rendering the search results, and ii. checking those URLs against popular filter lists (as described in Section 3.2). These URLs comprise both the sub resources (e.g., scripts, images, videos) loaded by the results page and the third-party requests made using the Web networking APIs (e.g., XMLHttpRequest, fetch(), web sockets).
\
We note that we were only able to measure the clientside network behavior of each search engine, and could only observe whether the search engine pages themselves were sharing information with known trackers. We were not able to measure how or if each search engine communicates with trackers on the server-side.
4.2 When clicking on an ad
Next, we measure how user privacy is affected after the user clicks on an ad, but before the user has arrived at the ad’s destination (usually, a page controlled by the party placing the advertisement). This step of the process involves systems run by both the search engine itself and the advertising platform paying for the ad.
\
During this stage, the advertising system may try and accomplish several goals, including fraud detection (i.e., attempting to detect if the “click” was the result of an automated system, intending to increase how much the advertiser pays the search engine) and user profiling (i.e., recording information about the user clicking the ad to combine with existing user profiles). Simultaneously, the search engine may use this step to try and achieve other goals, including quality of service measurements (i.e., ensuring that advertisements render correctly) or additional user profiling (i.e., recording which ad the user clicked to “enrich” whatever information the search engine may have about the user).
\
We find that the measured search engines vary widely in how they treat user privacy when the user clicks on an ad. However, we also find that the advertising systems engage in privacy-harming behaviors and share user identifying information with third parties across all measured search engines, despite the privacy-focused branding adopted by some search engines.
\
4.2.1 Search engine page behaviors. First, we measured what behaviors the search engine’s page engages in after the user clicks on an ad but before the browser begins navigating away from the search engine’s page (and towards the advertisement’s destination page). These behaviors might be things like recording which advertisement the user clicked on or how long the user waited before clicking, and are implemented with browser APIs like “onclick” handlers and “ping” attributes [16].
\
We measured each search engine’s post-click behaviors by recording what network requests happened on the page after each advertisement was clicked on. We find that all search engines record additional information about the user and/or the user’s click, after the user has clicked on an ad.
\
Bing. Clicking on an advertisement on Bing results in additional first-party (i.e., within Bing) network requests. In all iterations, clicking caused a request to be sent to https://bing.com/fd/ls/GLinkPingPost.aspx. These requests included several query parameters, including the clicked ads’ destination websites. Furthermore, these requests include user identifiers, for instance, communicated in the MUID cookie –A cookie identifying unique web browsers visiting Microsoft sites-[6].
\
Google. Clicking on ads on Google results in additional first-party web requests. In all cases, the browser sends POST web requests to https://google.com/gen_20?. These requests include user identifier values communicated in cookies such as NID and AEC [7].
\
DuckDuckGo. Clicking on an advertisement on DuckDuckGo results in additional first-party network connections to https://improving.duckduckgo.com. These requests include several query parameters, such as the search query, the ad provider (Bing in all cases), and the destination URL of the clicked ad. Next, the browser sends an additional network request that fetches a JavaScript file served from https://duckduckgo.com/y.js. This request includes several query parameters containing information about the ad and the link to which the user should be redirected (link to Bing servers). We note that none of the query parameters nor the cookies sent with these web requests matched our user heuristics for user identifiers.
\
Qwant. When clicking on an advertisement on Qwant, a first request is sent to https://qwant.com/action/click_serp, including information about the user’s browser, such as the type of the device and the browser language, along with the search query. Furthermore, this request contains information on the clicked ad (e.g., its position on the results page and the destination website). Then, another request is sent to https://api.qwant.com/v3/redirect/, including the URL to direct the user to. These two connections do not include user identifiers as query parameters nor as cookies values.
\
StartPage. Clicking on an advertisement on StartPage results in an additional first-party request to https://startpage.com/sp/cl. This request includes information about the position of the clicked ad on the results page, but does not include the ad’s destination URL. Similar to DuckDuckGo and Qwant, requests to StartPage servers do not include user identifiers.
\
In summary, we find that all search engines, traditional and privacy-focused alike, record information about users’ ad clicks. They all collect data about the clicked ad, such as its position on the results page or destination URL. However, only traditional search engines (Google and Bing) include user identifiers with web requests to their servers.
\
4.2.2 Navigation Tracking. Next, we measure whether the advertising systems in search engines engage in navigationbased tracking, a technique for tracking users that circumvents browser privacy protections by directing a user through otherwise unrelated sites. Section 2.2.2 provides a high-level summary of how navigating tracking works and why it is an effective method of circumventing tracking protections in many browsers. We find that most of the search engines in our data set engage in navigation-based tracking at least some of the time. Further, we find that the privacy-focused search engines engage in navigation-based tracking for the majority of placed ads.
\
\
We measure the navigation tracking we observed on the selected search engines in three dimensions: i. the distribution of how many sites the user is “bounced” through when they click on an ad on each search engine, ii. how many different organizations a user is exposed to during navigation tracking episodes (distinct from the number of pages or domains), and iii. the distribution of the number of sites in the redirection path that store user-identifying cookies.
\
Number of sites visited. Figure 4 presents the distribution of the number of different sites (i.e., 𝑒𝑇 𝐿𝐷 + 1) each search engine directs the user through when clicking on an ad. We observe that clicking on an ad on Bing generally results in being redirected through the fewest number of sites (96% of ad clicks on Bing result in no other site being visited except for Bing and the final destination site). Clicking on sites on DuckDuckGo, Google, and Qwant typically results in visiting one other site (respectively, 82%, 69%, and 72% of clicks result in an intermediate navigation to a site different than the search engine and the ad’s destination). Clicking on ads on StartPage resulted in (on average) visiting the largest number of different sites (93% of clicks resulted in visiting at least two sites other than StartPage and the ad’s destination).
\
Number of organizations visited. However, we note that all redirections are not equal in their privacy impact; the marginal privacy harm is generally much lower if a site redirects the user between two sites the company owns, versus the user being redirected between two sites owned by unrelated companies. More concretely, there is littleto-no additional privacy harm if Google bounces a user—and passes information about the user—from google.com to googleadservices.com, while there is privacy harm if Google bounces a user–and the user’s information—from google.com to facebook.com (i.e., Facebook learns new information they otherwise would not learn).
\
Understanding the privacy harm of navigation tracking requires considering which sites the user is being “bounced” between. Table 2 presents the five most common redirection paths for each search engine, and Table 7 in the appendix presents the most common sites in the redirection paths. Moreover, we group redirectors’ domains by the organization to which they belong using the Disconnect Entity List [2]. Table 3 presents the fraction of navigation paths that include a website from each organization across all search engines.
\
\
We observe that the impact of navigation tracking differs widely between search engines. On one hand, the navigation tracking that occurs from clicking on ads on Google results in little additional privacy harm; the most commonly immediately visited sites are also operated by Google (i.e., googleadservices.com and ad.doubleclick.com). On the other hand, we find that navigation tracking significantly harms user privacy on privacy-branded search engines. In all three cases, users are either usually directed to Bing sites (100% and 76% of the time for DuckDuckGo and Qwant, respectively) or Google sites (100% of the time for StartPage).
\
While these results are alarming—since these are search engines advertising that they are privacy-preserving —they are not inexplicable. DuckDuckGo and Qwant rely on Bing to provide search ads, and StartPage relies on Google.
\
Number of sites that identify users. The extent of privacy harm resulting from bounce tracking depends on two key factors: the behavior of the redirector (i.e., whether the redirector stores user identifying cookies) and the type of cookie storage used by the browser (flat or partitioned). The lowest level of privacy harm occurs when the redirector does not store any user-identifying cookies. In this case, the redirector can infer the source and destination of the navigation event (i.e., the search engine and the ad’s website). However, if the user navigates through the same redirector multiple times, the redirector cannot aggregate the tracking data from different visits to the same user.
\
In contrast, if the redirector sets UID cookies on users’ browsers, it can combine tracking data each time the user bounces through it. Specifically, if a user clicks on multiple ads on the same search engine and is redirected through the same redirector each time, the redirector can aggregate all the websites the user has visited. Moreover, if the user’s browser has flat cookie storage, the redirector can potentially aggregate the user’s activity and match it to the same user instance on every website where the redirector has a script.
\
\
\
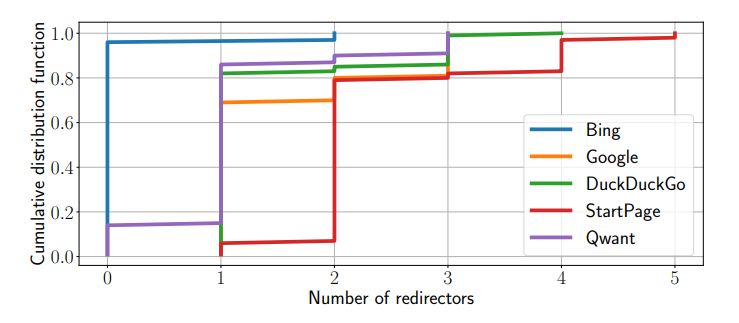
Figure 5 presents the distribution of the number of different redirectors in the navigation paths that store UID cookies for each search engine, and the Table 4 lists these redirectors that store UID cookies on users’ browsers. Our observations indicate that the level of privacy harm resulting from bounce tracking varies considerably across different search engines. While the navigation tracking that occurs when users click on ads on traditional search engines appears to cause little privacy harm, as users are identified by sites operated by third-party entities in only 4% and 8% of navigation paths for Bing and Google, respectively. In contrast, for the three privacy-branded search engines, users are identified by sites operated by third-party entities in most cases. Precisely, more than 95% of users clicking on ads on DuckDuckGo, StartPage, or Qwant are identified by Bing, and Google identifies users clicking on ads on StartPage in 100% of cases. As a result, Google and Bing might associate the destination website visited by the user through the advertisement to the user profile, especially if the user’s browser has flat-cookie storage.
\
4.3 After clicking on an ad
Finally, we measure how user privacy is impacted once the user has “finished” clicking on a search ad and has arrived at the advertiser’s page. We measure how the search engine/advertiser relationship effects user privacy in two ways: first, by measuring whether advertisers include trackers or other known-privacy-harming resources, and two, by measuring if and what kinds of information the search engine’s advertising system provides to the advertiser (in the form of user-describing query params). This first measure relates to whether the search engine requires advertisers to abide by privacy-respecting practices; the latter measure relates to whether search engines’ advertising systems collude with advertisers to aid advertisers in profiling visitors.
\
Redirectors in navigation paths can aggregate more data about the user’s behavior if they have scripts on the ads’ destination websites. For this, they need to match users using either third-party cookies if they are enabled by the browser or UID smuggling. We investigate whether redirectors can aggregate users’ activity on ads destination websites by analyzing online trackers, whether they receive UID as query parameters, and whether they store them. We recorded these requests by keeping the crawlers on the ads’ destination pages for 15 seconds for all iterations.
\
4.3.1 Requests to online trackers. We first measure whether search engines protect their users by requiring advertisers to be privacy-protecting. We measure this by loading the website each clicked search advertisement leads to, recording the URLs of all sub-resources and network requests made when loading and executing the page, and comparing those URLs against EasyList and EasyPrivacy.
\
We find that 93% of the web pages users are taken to when they click on ads on both “standard” and “privacy-focused” contain many privacy-harming resources. Broken down by search engine, we observed 277, 218, 326, 437, and 260 different tracker third parties over all iterations, and a median of 9, 11, 6, 8, and 6 different online trackers per iteration for Bing, Google, DuckDuckGo, StartPage, and Qwant, respectively.
\
In order to understand which companies track users on ad destination pages, we group the domains that observed tracking resources are served from by “entity” using the Disconnect Entity List [2] For example, using the entity list, we group tracker resources served from the domains google. com and doubleclick.com to the same entity (i.e., Google). Table 5 presents the top entities of trackers we observed on ad destination pages. For instance, we see that Google is the top entity for online trackers on destination pages for StartPage (36%), and we saw that all StartPage redirection paths go through Google servers. Hence, if the browser implements a flat cookies storage, Google can match the StartPage user on the ads destination website and aggregate data about his activity on it in 36% of the cases. We make the same observation for Microsoft trackers on Qwant (4.3%).
\
4.3.2 User identifiers. Finally, we measure if the advertising systems of the search engines aid advertisers in tracking users across sites by transmitting unique identifiers (or other personal or otherwise individual values) across site boundaries through query parameters.
\
As discussed in Section 3.2, this technique is sometimes called UID smuggling and is a common technique trackers and sites use to circumvent browser privacy protections (such as blocking third party cookies or partitioning browser storage). For example, if an advertiser places an ad for https://site.example, the advertising system might collude with the advertiser to allow the advertiser to profile the user by appending unique identifiers to the destination URL.
\
\
\
The search engine’s advertising system might, for example, append information the advertising system knows about the user to the advertiser’s destination URL (creating a URL like https://site.example?user_id=, so that the advertiser can learn more about the user, harming the user’s privacy.
\
We measure whether search engines’ advertising systems collude with advertisers to track users across sites by examining the query parameters the search engine (or other intermediate party in a navigation chain) includes in the URL of the advertiser’s destination page. We collect all of the query parameters in the destination ad URLs and extracted values that appeared to be unique identifiers using the heuristics described in Section 3.2.
\
We find that advertising systems collude with advertisers most of the time across all search engines, even private ones. Clicking ads on all five search engines resulted in user identifiers being passed to advertisers. We found user identifiers in query parameters in 80%, 94%, 68%, 92%, and 53% for Bing, Google, DuckDuckGo, StartPage, and Qwant, respectively. Most of these parameters are MSCLKID (Microsoft Click Identifier) or GCLID (Google Click Identifier), two unique identifiers used for ad-click tracking. MSCLKID is added by Microsoft Advertising and GCLID by Google Ads when users click on their respective ads. Advertisers use these IDs to identify and track ad clicks; advertisers might store clicktracking first-party cookies to track actions taken after the ad click [14, 24, 25]. Table 6 represents the fraction of iteration where the web request to the ad’s destination page included MSCLKID, GCLID, or other parameters. We can see that in search engines that use Microsoft advertising (DuckDuckGo and Bing), we find both MSCLKID and GCLID. However, in ones that use Google advertising (Google, StartPage, and Qwant), we do not find MSCLKID.
\
Moreover, we investigate whether advertisers persist the UID query parameters they receive. We cross-reference values obtained from destination pages’ first-party storage (e.g., cookies and localStorage) with the query parameters these pages receive. We find that MSCLKID values are persisted in 15%, 17%, and 1% of cases for Bing, DuckDuckGo, and Qwant, respectively. As for GCLID, we find that a cookie is created in 5%, 10%, and 13% of cases for Bing, Google, and StartPage.
\
[6] https://learn.microsoft.com/en-us/clarity/cookie-list
\
[7] https://policies.google.com/technologies/cookies
Welcome to Billionaire Club Co LLC, your gateway to a brand-new social media experience! Sign up today and dive into over 10,000 fresh daily articles and videos curated just for your enjoyment. Enjoy the ad free experience, unlimited content interactions, and get that coveted blue check verification—all for just $1 a month!
Account Frozen
Your account is frozen. You can still view content but cannot interact with it.
Please go to your settings to update your account status.
Open Profile Settings